


Cost & Efficiency Focused Models: New Releases and Overview Deck
Cost & Efficiency Focused Models: New Releases and Overview Deck
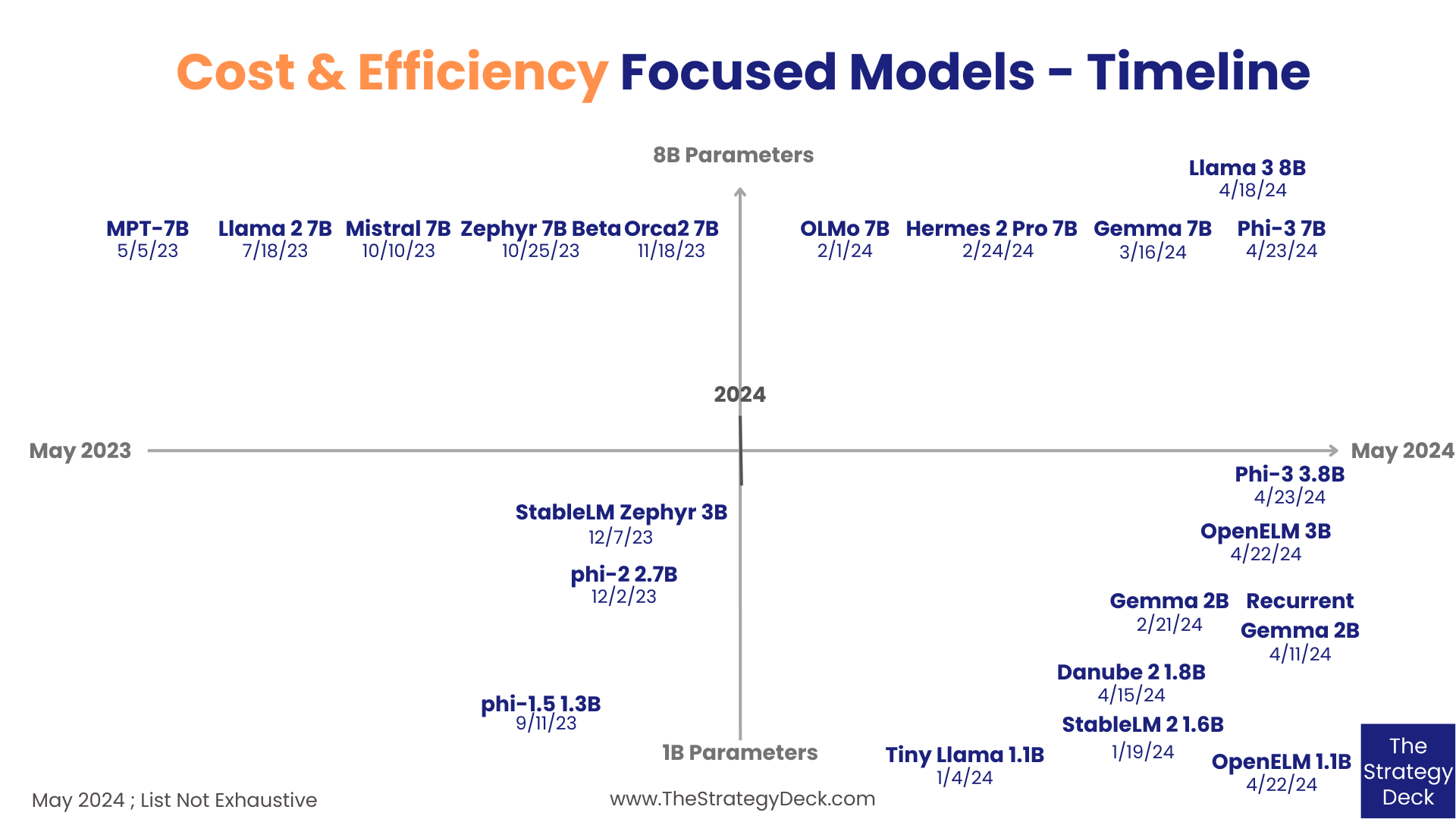
Recently Released Small Language Models Include OpenELM, phi-3, Hermes 2 Pro, OLMo and RecurrentGemma

The category of foundation models developed for cost and efficiency (with sizes between 1B and 8B parameters) has been growing a lot in the past few months, with new releases from large and smaller tech companies and research institutions. They help in a variety of ways:
Show new ways to train models at a lower cost on hardware that is more easily accessible
Enable more researchers and companies to build their own models and experiment with a larger diversity of use cases and applications
Advance methods for efficient training and inference, which in turn makes it more feasible for companies with products with large customer bases to add AI features
The latest releases in this category fit all of the points above and advance small models in a variety of directions. For example:
Apple’s OpenELM experiments with layer-wide scaling, a method for non-uniform parameter allocation, meant to help with model accuracy by finding a more efficient way of assigning attention heads and Feed Forward Network multipliers across transformer layers
OLMo, from the Allen Institue of AI, a very open model, complete with data, training and evaluation code, intermetdiate model checkpoints and training logs
RecurrentGemma, from Google, which applies the Griffin architecture to Gemma instead of transformers, in order to achieve more efficient inference for long sequences
phi-3, the latest in Microsoft’s phi collection, which experiments with training very small models on large quantities of high-quality, textbook-like data, in order to achieve similar performance to larger models
Hermes 2 Pro from Nous Research is fine-tuned from Mistral 7B with function-calling capabilities, in order to be integrated in AI agents
There are a lot of opportunity areas in this space, including the development of performant multilingual and multi-modal efficient models, the creation of even more specialized ones for various verticals, such as math and code, and even more efficient training and inference frameworks to make AI model building truly widely accessible.
Looking at 21 representative models from the past year, two sub-categories form: the 1B to 4B segment and the 7B and 8B one. Below are more details about the latest releases, as well as a link to The Data Room, this newsletter’s Premium content section (for Paid subscribers), which features the Cost & Efficiency Focused Models slide deck, with more insights and summaries of the 21 models.
Published April 23rd, 2014, phi-3 is a series of small models from Microsoft aimed at showing how vast and high-quality training data can produce efficient models with performance similar to that of larger ones. The mini version has 3.8B and was trained on 3.3T tokens, the small one has 7B and the medium 14B, both trained on 4.8T tokens.
Described in the paper titled “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone”, the model is available on the Microsoft Azure AI Studio, through Hugging Face and Ollama under an MIT license.
OpenELM was released by Apple on April 22, 2024, to explore more efficient training of small models through layer-wise scaling, a method of non-uniform allocation of attention heads and Feed Forward Network multipliers across transformer layers. The models come in pretrained and fine-tuned versions of 270M, 450M, 1.1B and 3B parameters. Apple also published code to convert the models to the MLX library for inference and fine-tuning on Apple devices.
Described in the paper titled “OpenELM: An Efficient Language Model Family with Open-Source Training and Inference Framework”, the model is available on Hugging Face under the Apple Sample Code license.
Danube 2 was publiched on April 15, 2024 by H2O, an AI cloud platform, in order to advance the science of small language models. Danube 2 has 1.8B parameters with 8k context length and was built using Llama and Mistral principles, including Flash Attention 2, Rotary Positional Embedding, Grouped Query Attention, RMSNorm, AdamW optimizer and the Mistral tokenizer.
Described in the paper titled “H2O-Danube - 1.8B Technical Report”, the model is available on Hugging Face under the Apache 2.0 license.

RecurrentGemma was published on April 11, 2024, by Google and is an application of the Griffin architecture to a small model similar to Gemma. Griffin replaces transformers and global attention with a combination or linear recurrences and location attention, in order to reduce memory use and enable more efficient inference on long sequences. RecurrentGemma is a 2B model available in pretrained and instruction-tuned versions.
The model paper is “RecurrentGemma: Moving Past Transformers for Efficient Open Language Models”, while the Griffin architecture is described in the “Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models” paper. RecurrentGemma is available on GitHub under an Apache 2.0 license.
Hermes 2 Pro was published on February 24, 2024 by Nous Research in order to produce an open source model optimized for function calling and deployment within AI agents. Hermes 2 Pro is a fine-tuned version of Mistral 7B and is available on Hugging Face and Ollama.
OLMo is a 7B very open model from the Allen Institue of AI and researchers from universities across the United States that is meant to advance open contributions to AI. Released with its complete building method, including data, training and evaluation code, intermediate checkpoints and training logs, OLMo is fully described in the “OLMo: Accelerating the Science of Language Models” paper and can be downloaded on GitHub and Hugging Face.
The comprehensive deck on Cost & Efficiency Focused Models, with insights and summaries of the models, is available in The Data Room for paid subscribers.
The Data Room
The Data Room is the repository with slide decks containing additional insights and the data behind the articles on The Strategy Deck. Paid subscribers get access to them, as well as the ability to ask for editable versions. Founding Members receive consultations with Alex on the AI market and product strategy for their company.
Check it out here.
This is a really good topic.