


Databricks - Open Source and B2B Network Effects in the Data Management Space
Databricks - Open Source and B2B Network Effects in the Data Management Space
Creating Network Effects for Short- and Long-Term Competitive Advantage in AI and Data

This article appeared earlier this week in the AI Supremacy newsletter.
The emergence of AI in the past year has increased the importance of unstructured data and of the tools needed to store, manage, transform and analyze it. Business data is the fuel for training and fine-tuning models for the entire spectrum of enterprise use cases and it is also an essential part of AI-based applications, especially when it comes to RAG systems.
Therefore, unstructured data management and analytics companies, such as Databricks, have become even more important for the AI ecosystem and have been growing together with it. But AI is not the only growth driver. In the past few years, Databricks has excelled at building around it an ecosystem of partners and contributors, as well as the associated network effects and the advantages that derive from them.
Network effects - the benefits gained from new users joining a platform and the competitive advantages that derive from the network - are core elements of marketplace companies, but they are not exclusive to them. B2B SaaS platforms are also building communities and marketplaces within or alongside their products that grow and maintain their business ecosystem.
This post is a look at Databricks’ product strategy and the types of network effects they are building around data management tools - an approach that helped the still private company get to a reported US$43B valuation as of September 2023, with US$1.6B revenue in the fiscal year ending in January 2024.
In a market that is virtually unlimited, as more digital data of all kinds is being created, stored and shared between companies every day, building and using network effects as a competitive advantage is valuable in the short- and long-term.
PRODUCT PORTFOLIO
Databricks provides a comprehensive platform for the entire data lifecycle, from ingestion and processing to analytics and machine learning. The core infrastructure is made up of the lakehouse architecture, which can handle both unstructured and structured data, on top of which the company offers a series of data processing, analytics and visualization tools. Within the lakehouse, the Delta Lake is the open source storage framework that provides the format for tables and operations. On top of the data is the Unity Catalog, the interface and permissions system to discover, describe, audit and govern data assets managed within Databricks.
Alongside the core offering is a collection of scaling and optimizations frameworks, as well as integrators and connectors to cloud computing providers (e.g.Azure, AWS) and 3rd-party analytics tools.
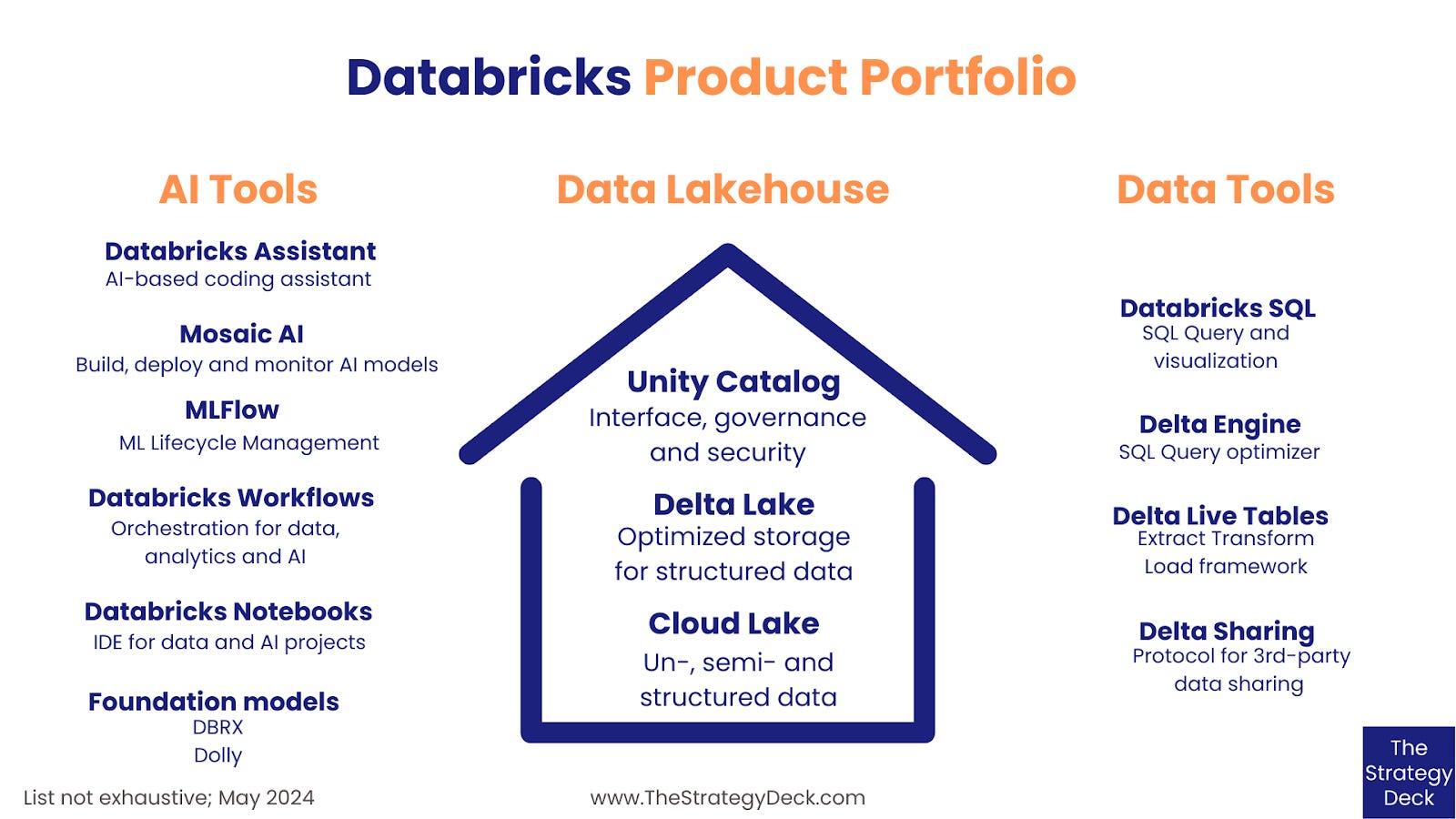
They include:
Databricks SQL - for SQL queries and visualization
Delta Engine - an optimizer for queries
Delta Live Tables - an ETL framework
Delta Sharing - open protocol for sharing with 3rd-parties
And in the past year, Databricks has focused on growing its collection of machine learning products. Alongside MLflow, the company offers tools to customize, fine-tune and build AI applications, as well as foundation models.
The AI tool catalog includes:
Databricks Assistant - an AI-based coding helper, currently in Public Preview
Mosaic AI - collection of tools to build, deploy and monitor AI models
MLFlow - ML lifecycle management
Databricks Workflows - orchestration for data, analytics and AI
Databricks Notebooks - IDE for data and AI projects
Foundation models - the DBRX and Dolly series
DBRX was published in March 2024 and is a General Purpose, mixture-of-experts model with 132B total parameters, of which 36B are active on any input. It was pre-trained on 12T tokens of text and code, with a 32k context window and it was designed to contain 16 experts and choose four of them when prompted. DBRX is available under the Databricks Open Model Acceptable Use Policy and it scores 68.9% on ARC-Challenges, 89% on HellaSwag, 73.7% on MMLU (5-shot), 66.9% on GSM8k and 70.1% on HumanEval, according to its technical report.
Dolly 2.0, released in April 2023 is a 12B, open source parameter model based on pythia from Eleuther AI and fine-tuned for instruction following.
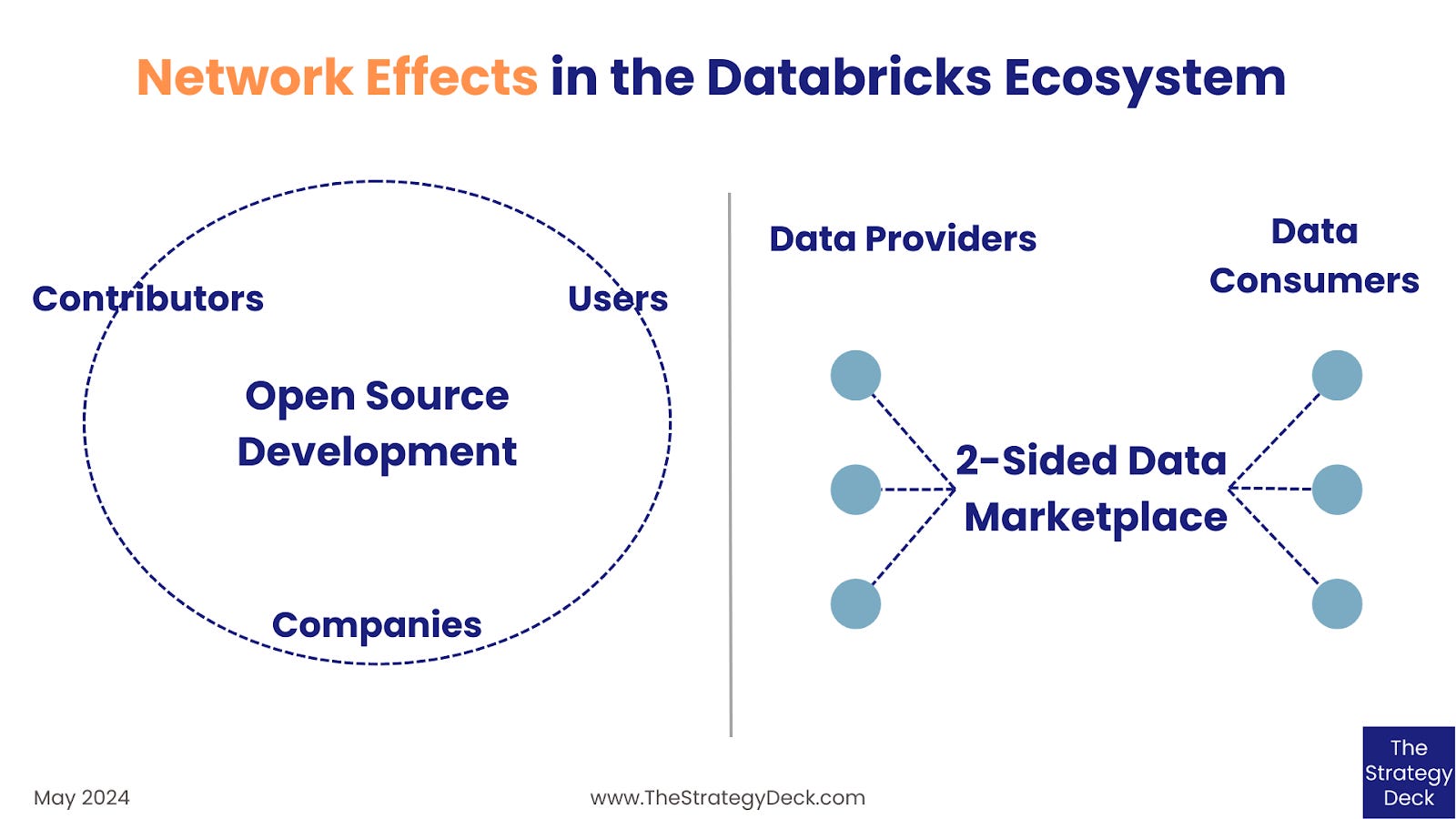
Databricks has two major sources of network effects: the open source development model and the data marketplace.
OPEN SOURCE NETWORK EFFECTS
Databricks has a significant history developing in the open and is a strong contributor to open source, from its technological foundations using Apache Spark to more recent products, such as MLflow and Delta Sharing.
Open source development creates many advantages for a company, including increased innovation and collaboration with experts across fields and geographies, enhanced transparency and security in the products, as well as the creation of a network of contributors, which benefits from network effects, which, in turn, improve the technology and the products that are being built.
There are four main types of network effects:
Direct same side, where people performing similar activities interact with each other for their mutual benefit
Direct cross-side, where people who contribute in complementary ways to the network interact with each other
Indirect same side, where people who perform similar activities benefit passively from each other’s presence and contribution to the network
Indirect cross-side, where people on complementary sides of the network benefit passively from the presence and activities of people on another side
In open source, direct and same side network effects accrue when each new volunteer who writes or reviews code increases the value of the technology and of the community for the other contributors. This happens because each new member brings her expertise and technical knowledge. More diverse and advanced skills enable better learning experiences and collaboration opportunities for the other developers to write even more innovative, performant and secure code.
And since open source communities also include volunteers and contributors who translate, evangelize, govern and market the technology, they also benefit from the network effects in similar ways to code contributors.
Another type of direct same side network effects enabled by open source are social, as members of the community create professional connections, which help them later in getting different jobs or collaborating outside of the project where they met.
The development of technical standards, such as for web technologies, is another benefit of direct and same side open source network effects, where developers from different companies come together to establish common syntax and performance standards, which in turn promotes technical transparency, interoperability and safety for the entire technology.
There are also direct cross-side network effects enabled by open source. Users of the technology or derived products have available diverse support communities, where they can get their questions answered. And if they need a particular feature to be built or bug fixed, they can reach out directly to the developers and advocate for their needs, thus adding to the functionality present in a product.
And other direct cross-side network effects accrue to companies who build products and services using open source technologies in the form of reduced maintenance and development costs.
These, and more, are network effects and advantages that companies who contribute to open source, such as Databricks, benefit from, directly and indirectly.
DATA MARKETPLACE NETWORK EFFECTS
In April 2023, Databricks launched a marketplace for data consumers and providers to share data sets and assets, such as ML models, notebooks, applications and dashboards. Based on the open Delta Sharing protocol, the marketplace benefits from the network effects inherent in 2-sided marketplaces that arise from the interdependence of the supply and demand sides.
The most important one is the direct, cross-side effect of the value increase of the marketplace for users on one side as the number of users on the other side grows. The more data providers there are, the more valuable the market becomes for data consumers. And vice versa. Growth on one side fuels the other one, creating a virtuous circle that becomes a competitive advantage for the company managing the platform.
The Databricks marketplace is aimed at three use cases: data monetization, data sharing with partners or suppliers and sharing with internal lines of business. Its value proposition is that it offers an open solution to securely share data independent of cloud providers and computing platforms. And data stored in open source formats, such as Apache Parquet and Delta Lake can be shared without replication or physical movement. Additionally, it offers Clean Rooms that enable safer, more private sharing of sensitive data.
OPEN SOURCE AND B2B NETWORK EFFECTS IN AI
Open source development has been an important driver for AI for a long time, as significant frameworks such as PyTorch and TensorFlow, as well as the Apache Spark and Delta technologies have been built in the open. And the recent growth in ML models that are accessible, to various degrees of openness, through Hugging Face, further augment the importance of community-based, collaborative development.
Databricks has been founded on open source and continues to adopt and extend such technologies while participating in the networks enabled by this type of development and their network effects. And, at the same time, is investing in the data marketplace, with its own virtuous circle of growth and supply and demand sides.
The rapid growth of AI in the past year has been driven by tremendous technological innovation and a considerable part of it has been in the open and has happened through communities of data scientists, engineers and practitioners, collaborating and exchanging ideas to benefit users of AI applications and the world at large.
