

Data Automation and Orchestration Tools Range from Specialized LLM App Building Frameworks to General Purpose Feature Platforms
It Is a Broad Sector Fueled by the Rise of Generative AI, Wide Range of Data Types and Diverse Needs of Companies for Customized Tools and Unique Workflows

Data automation and orchestration tools take up the task of collection, organizing, cleaning and managing the data needed to run ML-based applications. They significantly reduce the manual effort required to handle vast amounts of data and enable developers to focus on the actual engineering and optimization of the models and the applications that run on top of them.
At their core, they combine data from multiple sources, dealing with different formats and structures, and perform data transformations to make it suitable for specific machine learning algorithms. They also do cleaning operations, missing values input and outlier detection.
Common features of data automation and orchestration tools are:
Secure and scalable storage
Dataset version control
Collaborative workflows
Data integrity and consistency
Data profiling and anomaly detection
Data validation and cleansing
Task scheduling and dependency management
Workflow monitoring and vizualization
Error handling and retry mechanisms
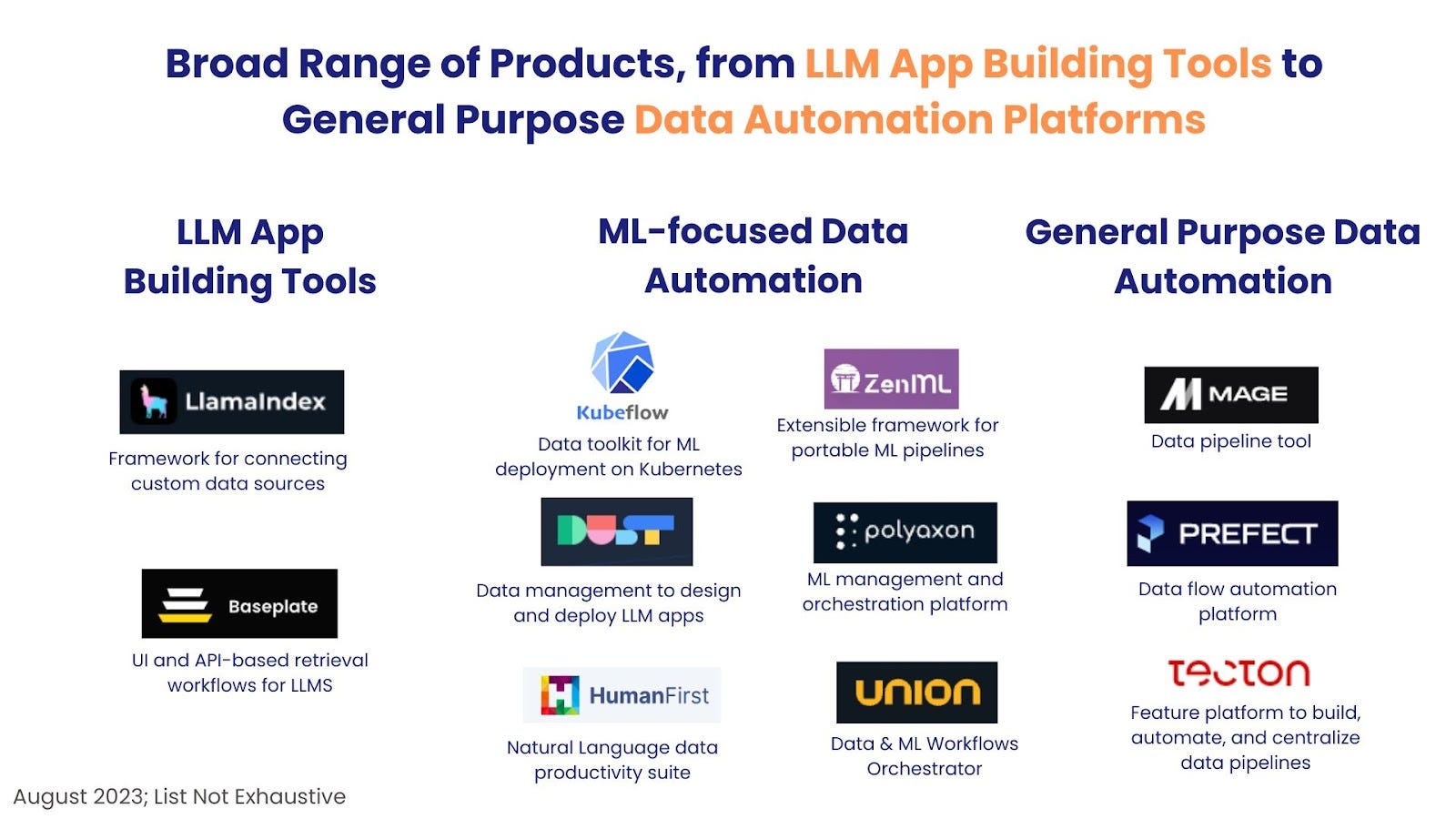
It is a broad sector, which spans from ETL tools to specialized LLM app building frameworks and general purpose data automation platforms. This breadth is the result of several factors. First, the exponential growth of the types and amounts of data sources requires a versatile range of tools to handle diverse data types and structures. Second, the rise of cloud computing and distributed architectures adds layers of complexity, requiring solutions to manage data across various platforms and environments. Third, the need for real-time insights and rapid decision-making has prompted the development of tools that can expedite data processing and analysis. And the large variety of industries and companies using data requires customizable solutions that can adapt to unique workflows and compliance requirements.
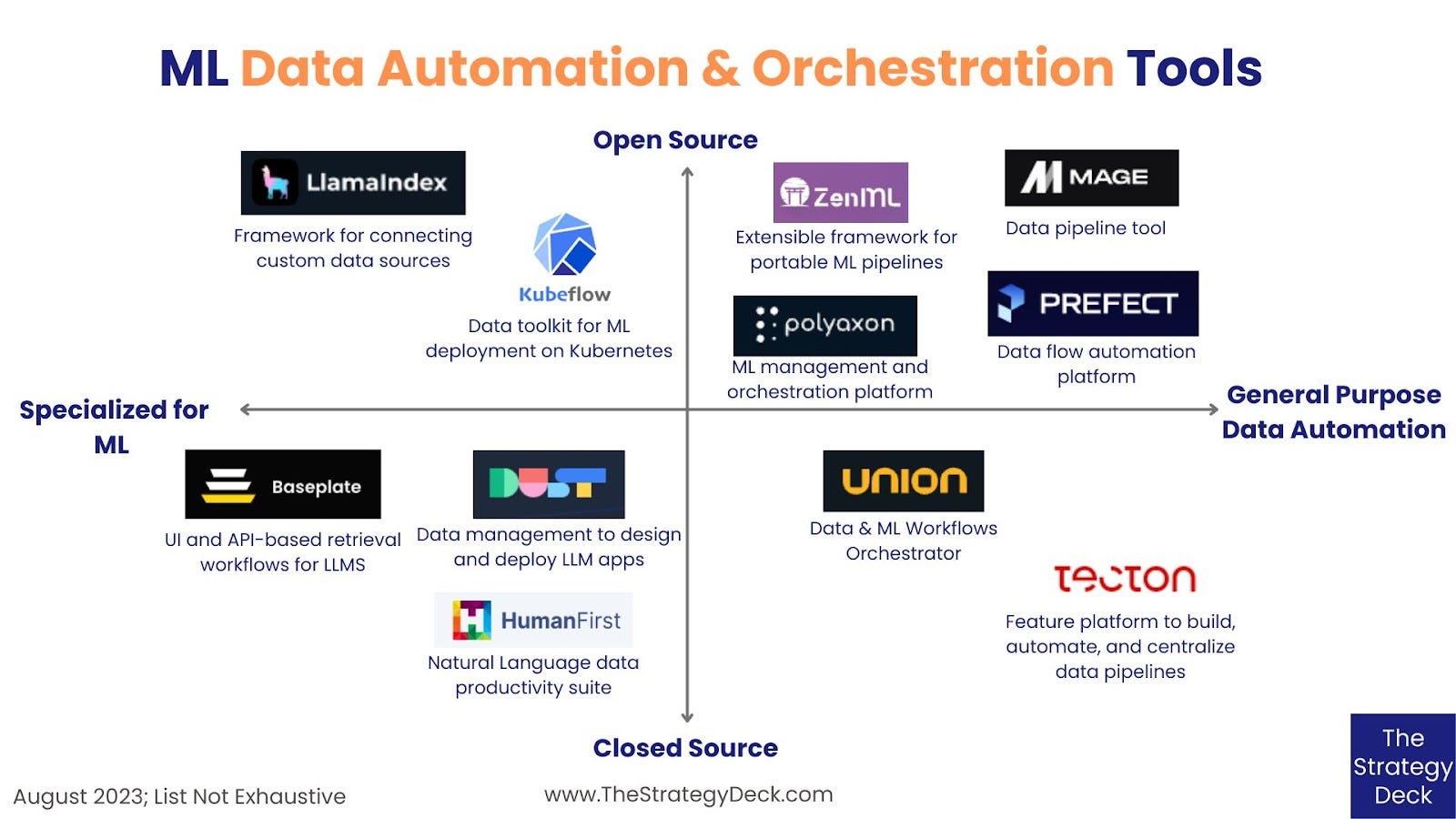
Below is a snapshot of some of the companies and types of products in this space.
ETL (Extract, Transform, Load) tools play an essential role in retrieval augmented generative AI applications. They facilitate the extraction of data from various sources, including databases, web APIs, text files, and more. The extracted data is then transformed and preprocessed to ensure consistency, accuracy, and compatibility with the target AI model.
During the transformation phase, ETL tools help to clean the data, remove duplicates, handle missing values, and preprocess the text data for NLP tasks. Additionally, data augmentation techniques can be applied to increase the diversity of the dataset.
The loading phase of ETL involves storing the transformed and augmented data into a suitable database or data warehouse. The AI application can then query this data through retrieval to find the relevant information and context for generating responses.
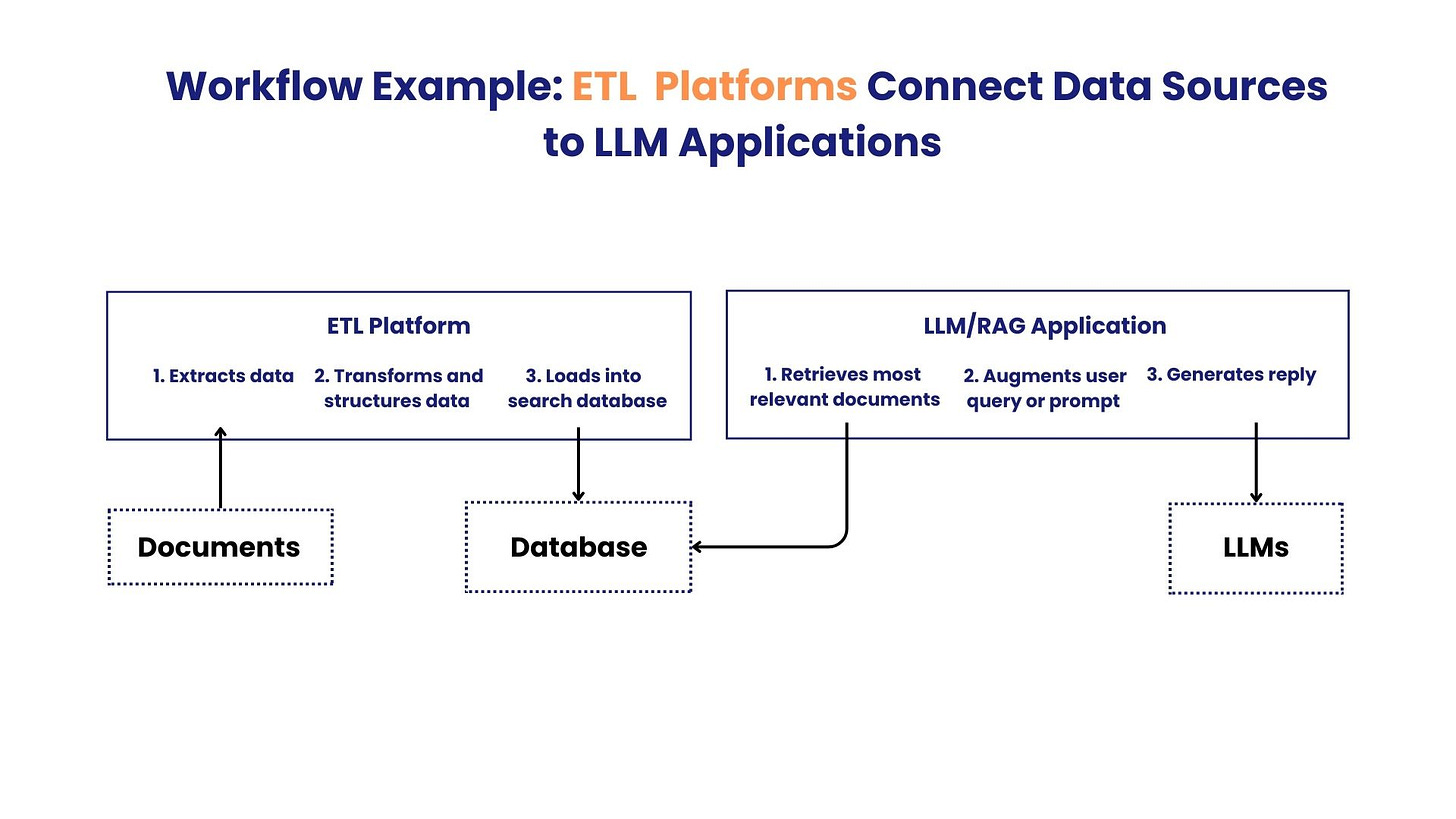
Credit: Jeremy McMinis from Sawtooth Data
Data automation platforms specialized for ML applications, such as HumanFirst, ZenML and Polyaxon, are more complex solutions which offer a comprehensive suite of tools that include data preprocessing, transformation and scaling features. These platforms often offer model versioning and management, allowing data scientists to keep track of different iterations of their models, share them with team members, and roll back to previous versions when needed. For deployment, ML data automation platforms provide model serving functionalities, which make it easy to deploy ML models into production environments. They handle scaling, monitoring, and maintaining the deployed models, which made for reliable AI applications.
Some of the companies in this space are:
LlamaIndex wants you to “Unleash the power of LLMs over your data.” To do that, it provides a flexible framework for connecting custom data sources to large language models. The tool supports data ingestion, data indexing and a query interface that accepts input prompts and returns knowledge -augmented responses. LlaimaIndex is based in San Francisco, CA and it last raised a $US8.5M Seed round in June 2023.
Baseplate promises high-performance retrieval workflows with no additional work. To support that, it provides a Ui and API-based workflow manager to handle embeddings, storage and version control, a unified hybrid database and the ability to manage your vector database like a spreadsheet and edit the vectors manually or programmatically. With headquarters in San Francisco, CA Baseplate is backed by YCombinator and it last raised a $US500k Pre-Seed round in April 2023.
Dust specializes in the building of custom LLM apps on top of your company data. It provides a flexible framework to define and define enterprise AI applications that is built to handle entanglement and speed, introspection and versioning. With headquarters in Paris, France, Dust last raised a EUR5M Seed round in June 2023.
Kubeflow is a non-profit organization which provides a Machine Learning toolkit for Kubernetes. It aims to make deployments simple, portable and scalable and it supports with data preparation, model training, prediction serving and service management. Its headquarters are in Mountain View, CA and it provides B2B SaaS services.
HumanFirst claims it is the fastest way to build customer AI you can trust and it provides a Natural Language data productivity suite to design, test and launch high-quality NLU models and prompts for business insights, automation and CX. It offers a low-code environment that can track data origins, developer-friendly APIs and ALI, revisions, diffs, revert, cloning and horizontal scaling functions. HumanFirst is based in Montreal, Canada and it last raised a $US5M Seed round in July 2023
ZenML aims to power MLOps workflows on any infrastructure through its extensivle framework for creating portable, production-ready ML pipelines. Its product is pipiline-agnostic and supports deployment locally, on open source tools or managed orchestration. The ZenML Platform Sandbox provides a one-click deployment platfor for a pre-built ephemeral MLOps stack, simplifying the deployment process. ZenML is based in Munich, Germany, and it last raised a $US2.7M Seed round in December 2021
Polyaxon provides ML Operations and Infrastructure to reproduce automate and scale data science workflows. Polyaxon Cloud is a fully managed control plane for deployment, orchestration, logging, backups, while Polyaxon EE is the on-premise Enterprise Edition and Poly axon Coimmunity the free version of the service with core features.
Union aims to converge and simplify AI, data and analytics. To this end, it provides Flyte, with workflow vizualization to monitor models and view training history, versionning and task level monitoring, as well as Union Cloud for Kubernetes-native data and ML workflows at scale and Union ML for microservices. Based in Bellevue, WA, Union last raised a $US19.1M Series A in May 2023
Mage wants to “give your data team magical powers” with open source data pipeline tool that allows the building of real-time and batch pipelines to transform data using Python, SQL and R, so that you run, monitor and orchestrate thousands of pipelines without losing sleep. Based in Santa Clara, CA, Mage last raised $US6.3M Seed round in March 2023
Prefect provides tools to orchestrate and observe all of your workflows, like air traffic control for your data. It takes care of scheduling, infrastructure, error handling, retries, logs, triggers, data serialization, parametrization, dynamic mapping, caching, concurrency and more. Based in Washington, DC Prefect last raised a $US32M Series B round in June 2021
Tecton is a feature platform to build, automate and centralize data pipelines that is fully managed and cloud native, built for availability and scale and that integrates with storage and processing infrastructure. With headquarters in San Francisco, CA Tecton last raised a $US100M Series C in July 2022.
Whether you are building the prototype for a generative AI application, or need to orchestrate a complex data workflow, there is a broad selection of automation and orchestration tools at your disposal, You can go with established, general purpose tools that are robust, safe and flexible, or you can choose a solution specialized for ML and LLM workflows. Finally, if you prefer transparency and advanced customization options there is a good variety of open source tools to try.
Download the detailed market map and analysis on The Strategy Deck’s Resources page or directly here.
