

How Hugging Face and Kaggle Bolster the Open Source Machine Learning Community
The Key Components Are Collections of Models and Datasets, Model Deployment Infrastructure and Community Learning and Engagement Resources

Open source ML hubs, such as Hugging Face and Kaggle, provide a centralized platform for managing, sharing and deploying ML models. To do that, they work on fostering and supporting a diverse ecosystem of providers of foundational models, AI application developers and Machine Learning students and researchers. They do that by providing infrastructure to discover, fine-tune and deploy models and tools for the community of open source researchers and enthusiasts to come together and collaborate.
Key features of model hubs include:
Model repositories and discovery mechanisms
Collaboration and model sharing tools
Integration with ML workflows
Model versioning tools
Community, social and event platforms for developers, data scientists and contributors to the ecosystem
Hugging Face Is Building a Comprehensive Model Deployment Infrastructure and Open Source Community
Hugging Face is a hub for sharing, discovery and deployment of open source ML models with associated datasets, an application marketplace and access to all of the major compute providers. Founded in 2016 and headquartered in New York, NY, the company’s motto is “The AI community building the future.”
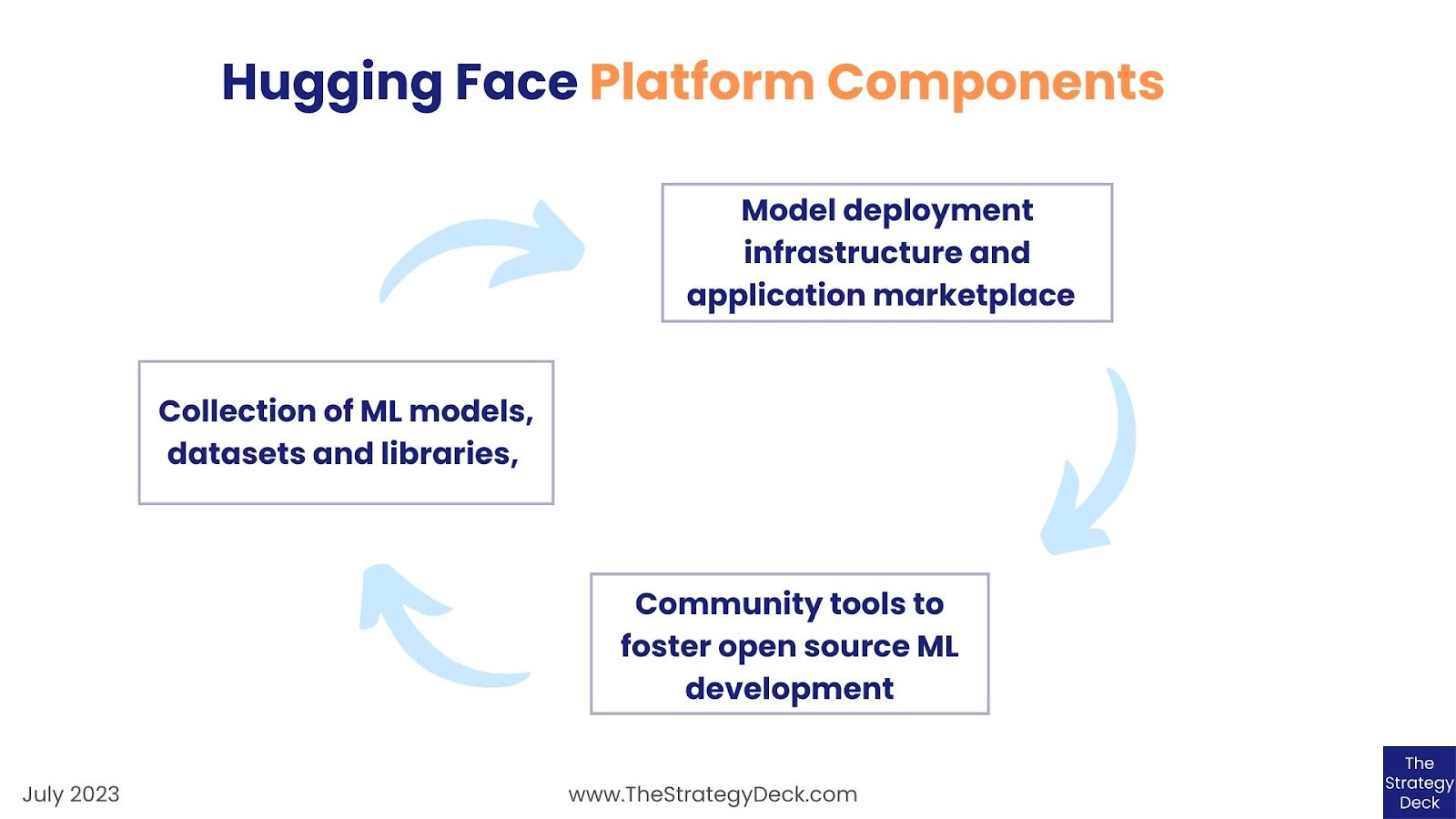
Hugging Face is built around three parts that complement each other: a collection of open source ML models and datasets, the infrastructure for model deployment and applications and the community and social tools to foster open source ML development, education and advocacy.
The collection of models and datasets is needed to enable the usage of the application infrastructure and the community and educational tools maintain and grow user engagement with open source ML and the Hugging Face platform.
The collection of ML models, datasets and libraries spans a large variety of tasks, languages and licenses. It includes:
Transformers Library to download and fine-tune pre-trained models
Accelerate library to train large models on distributed hardware
266,639 models (as of July 2023), including 689 from Meta, 594 from Google and 252 from Microsoft, and including 119,196 that work with the Hugging Face Transformers library, 110,665 with PyTorch, 8,563 with TensorFlow and 8,442 with JAX
47,376 datasets (as of July 2023) in over 200 languages and under 66 different open source licenses

The model deployment infrastructure represents Hugging Face’s core product offering and it consists of:
Inference Endpoints interface and API to deploy open source ML models directly from Hugging Face infrastructure, offered through a self-serve model with standardized pricing and an Enterprise model with custom pricing and dedicated support and SLAs
Features include autoscaling, access logs and monitoring, custom metrics routes, programmatic endpoint management and model rollback
Access to AWS, Microsoft Azure and Google Cloud compute power across major geographies
Enterprise Hub, the end-to-end platform to build AI with enterprise-grade security, access controls and dedicated support.
AutoTrain, a no-code solution to train, evaluate and deploy ML models, with support for CSV, TSV and JSON files and tasks such as text classification, text regression, entity recognition, summarization, question answering, translation and tabular.
Expert Acceleration Program which provides guidance from Hugging Face experts to help customers build better ML solutions, faster.
Optimum, the ML optimization toolkit for production performance focused on hardware-specific acceleration tools, such as Quantize, Prune, Train
Spaces, the application marketplace that enables ML apps building, hosting and sharing
Support for Streamlit and Gradio Python libraries

The community tools to foster open source ML development, education and advocacy include:
ML coding events, such as Open Source AI Game Jam and partnerships to build ML apps, such as StarCoder with ServiceNow
Courses on Natural Language Processing, deep reinforcement learning and audio data processing
Hugging Face for Classrooms with free teaching resources and support for students and professors
Documentation repository on building, deploying and managing open source ML applications
Open LLM Leaderboard for performance benchmarking
Daily Papers - Repository with links to Machine Learning research papers
Support forum and Discord discussion server
Hugging Face’s business model includes B2B SaaS for the Inference Endpoints, Enterprise Hub and AutoTrain products, consulting services sales through the Expert Accelerator Program and compute and storage distribution from the major cloud providers: AWS, Microsoft Azure and Google Cloud.
Sources of competitive advantage for Hugging Face include:
Network effects created through the community educational and advocacy tools and events
Economies of scale due to its role as an aggregator and distributor of compute and cloud storage resources
The vast collection of open source models and datasets which provide an entry barrier to potential new competitors in the space
Since its founding, Hugging Face raised a total of US$160.2M over 5 rounds:
US$100M Series C in May 2022
US$40M Series B in March 2021
US$15M Series A in December 2019
US$4M Seed in May 2018
US$1.2M Angel round in March 2017
Kaggle Invests in the Data Science Community and Empowers It with Open Source Models and Google Compute Infrastructure
Founded in 2010, Kaggle is best known for its data science competition platform and online community, where beginner and advanced scientists solve practical challenges using real world data. Notable competitions including one improving gesture recognition for Microsoft Kinect, making a football AI for Manchester City and improving the search for the Higgs boson at CERN.
Kaggle provides ML educational, experimentation and deployment products to three core audiences:
Learners, who engage in competitions, courses and use its public datasets
Developers, who get access to open source models and public notebooks
Researchers, who can host competitions and train their models with fatasets hosted on the platform
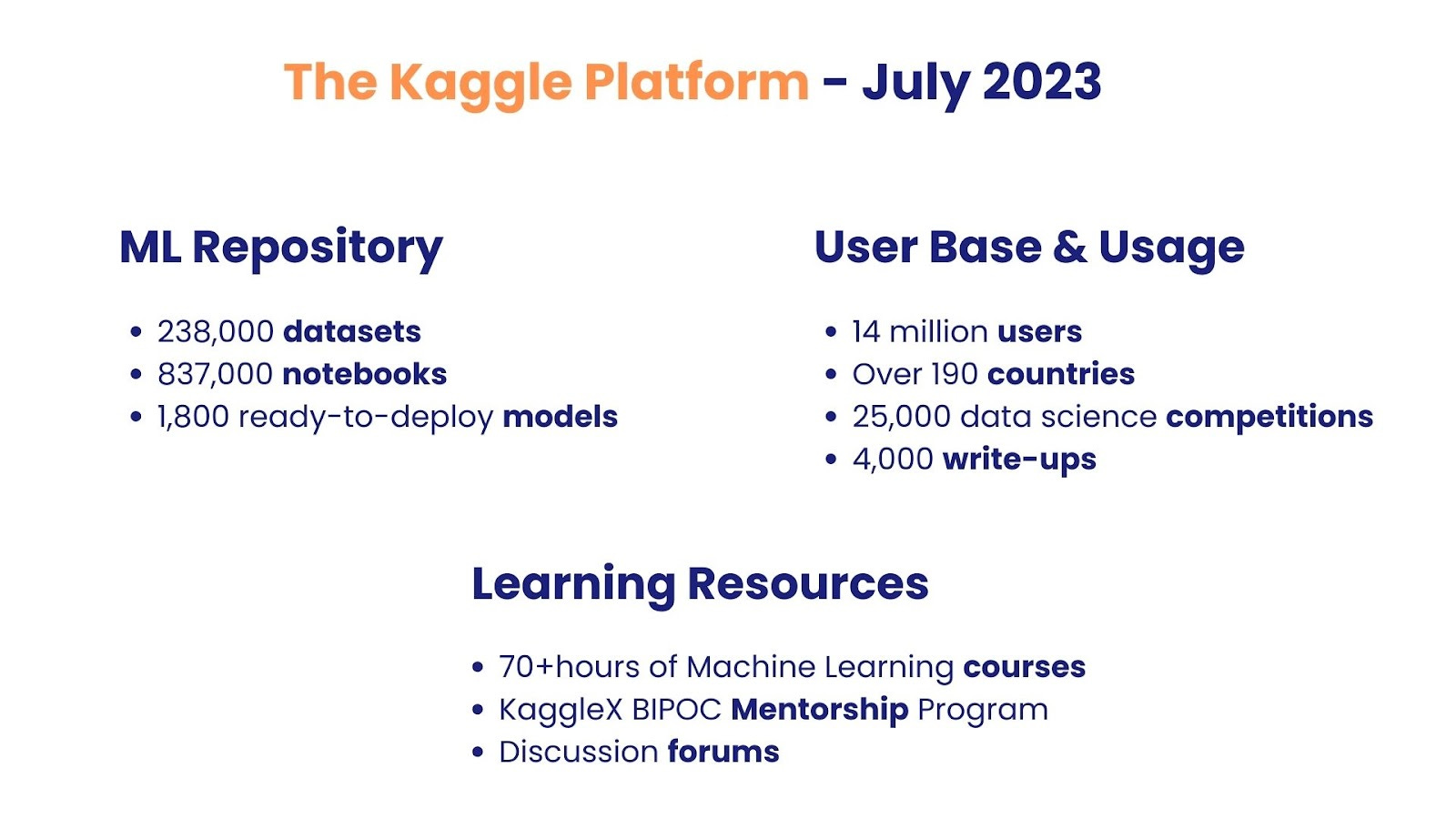
As of July 2023, Kaggle’s platform has:
ML repository
238,000 datasets
837,000 notebooks
1,800 pre-trained, ready-to-deploy models
User base and usage:
14 million users
Over 190 countries
25,000 data science competitions
4,000 write-ups
Learning resources:
70+hours of Machine Learning courses
Discussion forums
The core product which enables model deployment is Notebooks, a cloud computational environment that facilitates analysis and access to the necessary computing and storage resources. There are 3 types of notebooks: for R or Python scripts, for RMarkdown code and Jupyter notebooks. They come integrated with Google’s Cloud Storage, Big Query data warehouse and AutoML infrastructure. Each Notebook can be used with 12 hours of execution time for CPU (4 core, 30 GB RAM) and GPU (1 P100 core, 2 CPU cores, 13 GB RAM) sessions and 9 hours for TPU (4 CPU cores, 16 GB RAM) sessions, as well as 20 GB of storage.
With headquarters in San Francisco, CA, Kaggle is now a subsidiary of Google, after it was acquired in 2017.
Like the other sectors in the ML and AI space, open source model hubs are experiencing a lot of interest and growth from new and experienced data scientists, application developers, students and investors. It is exciting to see how active and resourceful the open source community is in developing and growing the use cases and benefits we get from ML tech.
