

ML Data Labeling Tools Structure Information to Make It Meaningful - Market Map and Analysis
The ML Data-Centric Segment is Growing in Multiple Directions, with Multi-Modal, General Purpose and Niche Tools for Manual and Programmatic Labeling

Data labeling is the process of identifying raw data (images, text files, videos, etc.) and adding one or more meaningful and informative labels to provide context so that a machine learning model can learn to make similar annotations.
Labeled data is important for improving the quality of ML models at the pre-training, fine-tuning and QA stages. Manual labeling employs specialized workers to annotate and provide meaning to a dataset. Programmatic tools work with labeling functions instead of individual labels, which can be applied to unstructured data to output training labels.
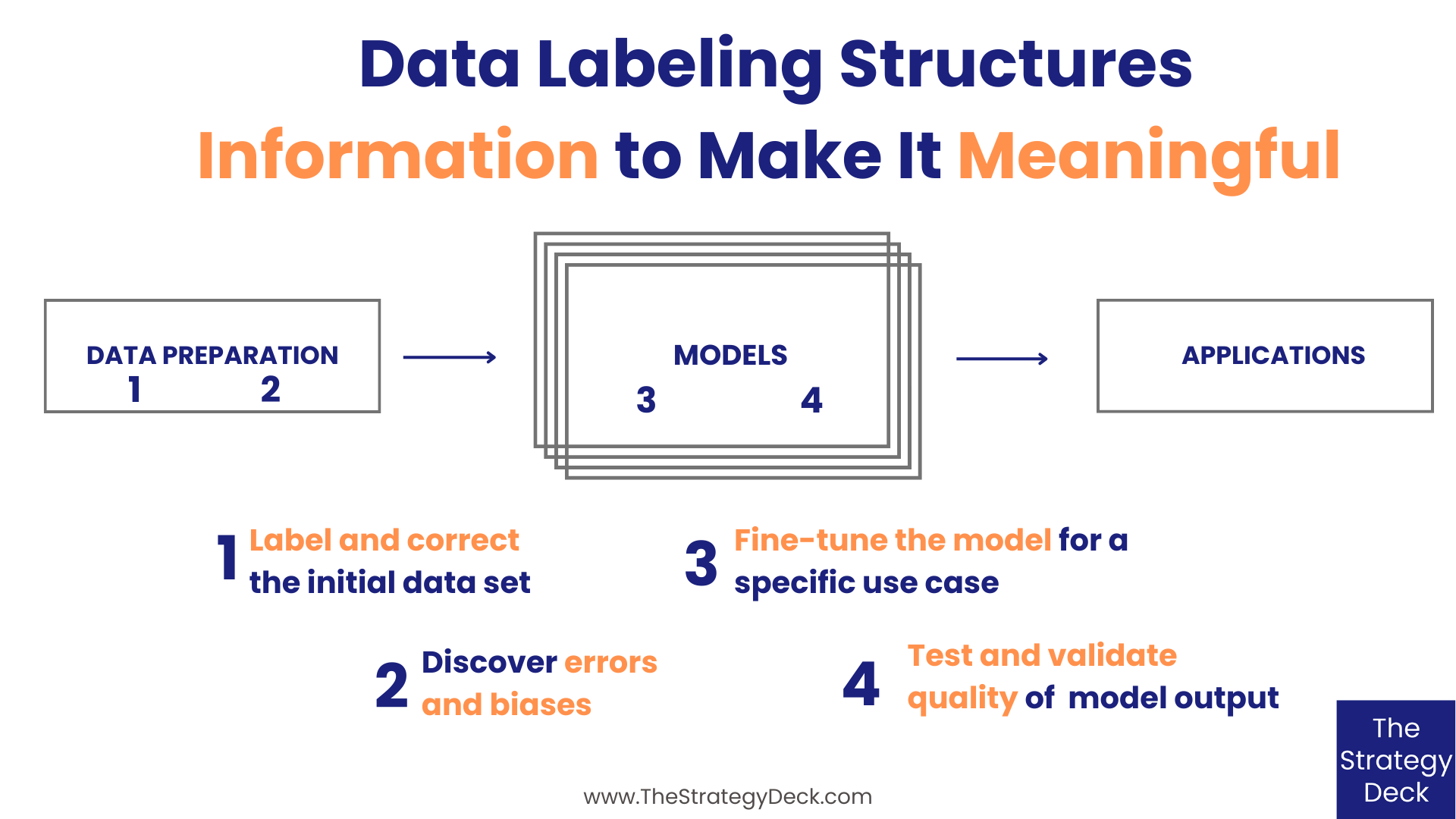
There are four functions that data labeling fulfills:
Annotate and correct the initial data set
Discover errors and biases
Fine-tune the model for a specific use case
Test and validate the quality of the model’s output
Features of labeling and annotation platforms include:
Support for relevant data types, including audio, video, text, 3D and sensors
Tools for collaboration between annotators, enabling multiple users to work simultaneously, track progress and communicate
Comprehensive and customizable annotation interfaces
Seamless integration with ML frameworks and Ops tools
Data versioning and auditing features
Data quality control features, such as inter-annotator agreement analysis, review workflows and data validation checks
Data export to relevant formats compatible with downstream ML pipelines
The most common data types are images, video and 3D point cloud for computer vision applications, text for natural language processing and audio for speech recognition.
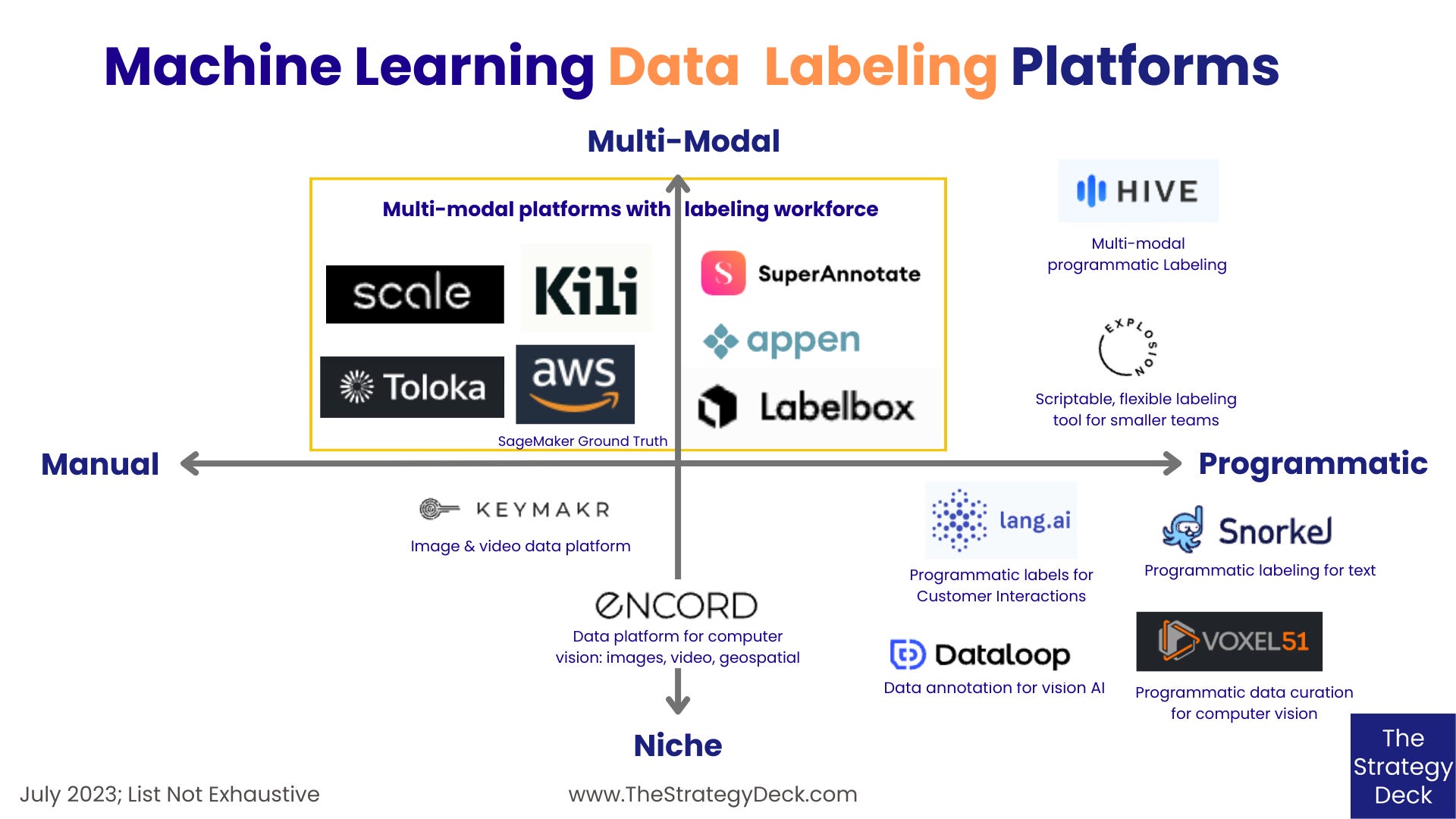
The main categories of data labeling ML platforms are:
Multi-modal platforms with labeling workforce
Tools focused on programmatic labeling
Specialized solutions for computer vision
Multi-Modal, General Purpose Tools Facilitate Manual Labeling
The typical offering for general purpose labeling tools includes:
Support for multiple data types
Integration with popular ML frameworks and Ops tools
Access to specialized labeling workforce
Programmatic QA
Companies in the space are:
Scale AI’s mission is to accelerate the development of AI applications. The company offers Scale Rapid with out-of-the-box workflows, Scale Spellbook to compare experiments and implement finetuning strategies, and a specialized labeling workforce to provide the necessary annotation input. Based in San Francisco, CA, Scale AI last raised a US$325M Series E in April 2021.
Toloka offers a data-centric environment to support fast and scalable AI development with the help of human insight. It has human-labeled data, ready-to-use pre-trained LLMs and Human-in-the loop flows for model evaluation and retraining. Based in Lucerne, Switzerland, Toloka’s mission statement is “Powering AI with human insight”.
Kili’s journey is to enable businesses around the world to build trustworthy AI with high-quality data and to that end it provides tools to annotate all types of data rapidly and accurately with customizable tasks, supervise data quality levels, and manage programmatic QA. Kili is based in Paris, France and it last raised a US$25M Series A in July 2021.
AWS SageMaker Ground Truth is Amazon’s tool for creating high-quality datasets. SageMaker Ground Truth Plus is a fully-managed service to create high-quality training datasets without having to build labeling applications or manage labeling workforces on your own, while SageMaker Ground Truth allows you to build and manage your own data labeling workflows and workforce.

SuperAnnotate’s tagline is “Your Ai Deserves SuperData” and it delivers on it with Data Studio, a tool to annotate, hire specialized classification workforce, manage annotation projects and ML Studio, which offers AI Data Management and curation, MLOps and automations, integrations and security. Based in San Mateo, CA, SuperAnnotate last raised a US$14.5M Series A in July 2021.
With the tagline “Unlock your data. Unleash your AI.”, LabelBox provides four tools: Catalog, to search and annotate unstructured data, Annotate, to label data with AI assistance and humans, Model, to prelabel data and evaluate models, and Boost, an on demand labeling service. Based in San Francisco, CA, LabelBox last raised a US$110M Series D in January 2022.
Appen’s tagline is “Confidence to Deploy World-Class AI” and it provides, among others, LLM data products for fine-tuning and red-teaming of models. Appen is a publicly traded company based in Chatswood, Australia.
Programmatic Labeling Tools Focus on Specific Data Types, Niches
Niches for programmatic labeling include:
Customer Interactions
Smaller teams
Specific data types: text, images / video
Companies in this space are:
Hive AI focuses on cloud-based AI solutions for understanding content, specifically its content moderation and labeling platform to classify and detect content attributes, search content and datasets and generate images and text from prompts. Based in San Francisco, CA, it last raised a US$Series D in April 2021.
Snorkel AI’s mission is to empower everyone to solve their most impactful problems through data-centric AI and to this end it offers Snorkel Flow to programmatically label training data and correct model errors through labeling functions, Snorkel GenFlow with instruction-tuning and RLHF to build, manage and deploy gen AI apps and Snorkel Foundry to pre-train domain specific LLMs by programmatically sampling, filtering, cleaning and augmenting of proprietary data. Snorkel AI is based in Redwood City, CA and it last raised a US$85M Series C in August 2021.

Lang.ai’s focus is to unlock the power of CX Data with easy-to-use-AI. The company provides Lang Data Operations, which auto-tags and routes tickets and automates workflows, Lang Optimize, which flags inefficient agent workflows, and Lang Predict, which pinpoints and notifies of issues affecting the customer journey. With headquarters in Madrid, Spain, Lang.ai last raised a US$10M.5 Series A in May 2022.
Explosion creates developer tools for AI and NLP and is the maker of spaCy and Prodigy. The latter is a scriptable, multi-modal data annotation tool which includes a Python library with pre-built workflows and command-line commands for various tasks, and well-documented components for implementing workflow scripts. Explosion is based in Berlin, Germany and it last raised a US$6M Series A in September 2022.
Voxel51’s mission is to bring transparency and clarity to the world’s data and it provides an open source toolkit that enables you to build better computer vision workflows, as well as VoxelGPT, an AI assistant for computer vision. Based in Ann Arbor, MI, Voxel51 last raised a US$12.5M Series A in September 2022.
Computer Vision Tools Allow Manual and Programmatic Labeling
Computer vision use cases include:
Healthcare
Drones and aerial imagery
Robotics
Autonomous vehicles
Agriculture
Media and content
Retail and commerce analysis
Companies in the space are:
DataLoop’s tagline is “The Data Engine for AI” and it provides products to power vision AI across industries with annotation tools, automatic annotations, workforce management, data QA and verification, integrated labeling services, while covering the entire data management cycle, from data labeling, automating data ops, deploying production pipelines, and human-in-the-loop. DataLoop is headquartered in San Francisco, CA and it last raised a US$325M Series E in April 2021.

Encord aims to help you “Unlock AI from Your Data” and provides an automatic annotation platform to accelerate data labeling with actionable insights to improve model quality and fix outliers in your training, as well as on-demand, specialized labeling services to help you scale
Keymakr’s tagline is “Better AI unlocks a better world” and it specializes in annotating videos and creating high-quality data for ML models. Keymakr is based in Tel Aviv, Israel
The need for specialized and factually correct AI applications is fueling the growth of the data labeling sector and we are only at the beginning. Whether manual or programmatic, any ML-based application needs corectly and thoroughly annotated data to be built and fine-tuned. I’m excited to see how large and diverse this segment will grow and to benefit from even more intelligent AI applications.
Download the detailed market map and analysis on The Strategy Deck’s Resources page or directly here.
