

Domain-Focused Models: Math LLMs
Open Source Models Trained for Mathematical Reasoning and Arithmetic

Are you building an AI application for finance, accounting, scientific research or tutoring? This post is about language models built to perform math.
The spectrum of mathematical tasks for AI models is wide and it includes:
Arithmetic - addition, subtraction, multiplication, division
Math word problems - scenarios presented in the form of descriptions of real-world situations, whose solution involves identifying mathematical concepts within them and performing operations
Geometry - problems which involve a spatial understanding of shapes, sizes and their relationships, as well as geometric principles, theorems and formulas
Theorem Proving - constructing logical proofs for specific dynamics and relationships between numbers
Chart and graph reasoning - the ability to read graphic representations of math concepts and apply logical reasoning, arithmetic and geometry
This article looks at representative math-focused LLMs that were released in 2023 and 2024, developed primarily for mathematical reasoning (word problems) and arithmetic. It is Part 5 of the series on growth vectors in the AI space. Part 1 and part 3 look at cost-focused LLMs, Part 2 is about General Purpose models and Part 4 is on LLMs developed for coding.
The models in this collection are:
EvoLLM-JP - a Japanese Math Model
Orca-Math - fine-tuned from Mistral 7B to excel on GSM8K
Llemma - a fine-tuned version of Code Llama on Proof-Pile 2
MetaMath - trained to specialize in mathematical reasoning with the MetaMathQA dataset
MAmmoTH - CoT and PoT fine-tuning for general math problem-solving
WizardMath - fine-tuning with Reinforced Evol-Instruct
GOAT - GOod at Arithmetic Tasks
EvoLLM-JP - Japanese Math Model
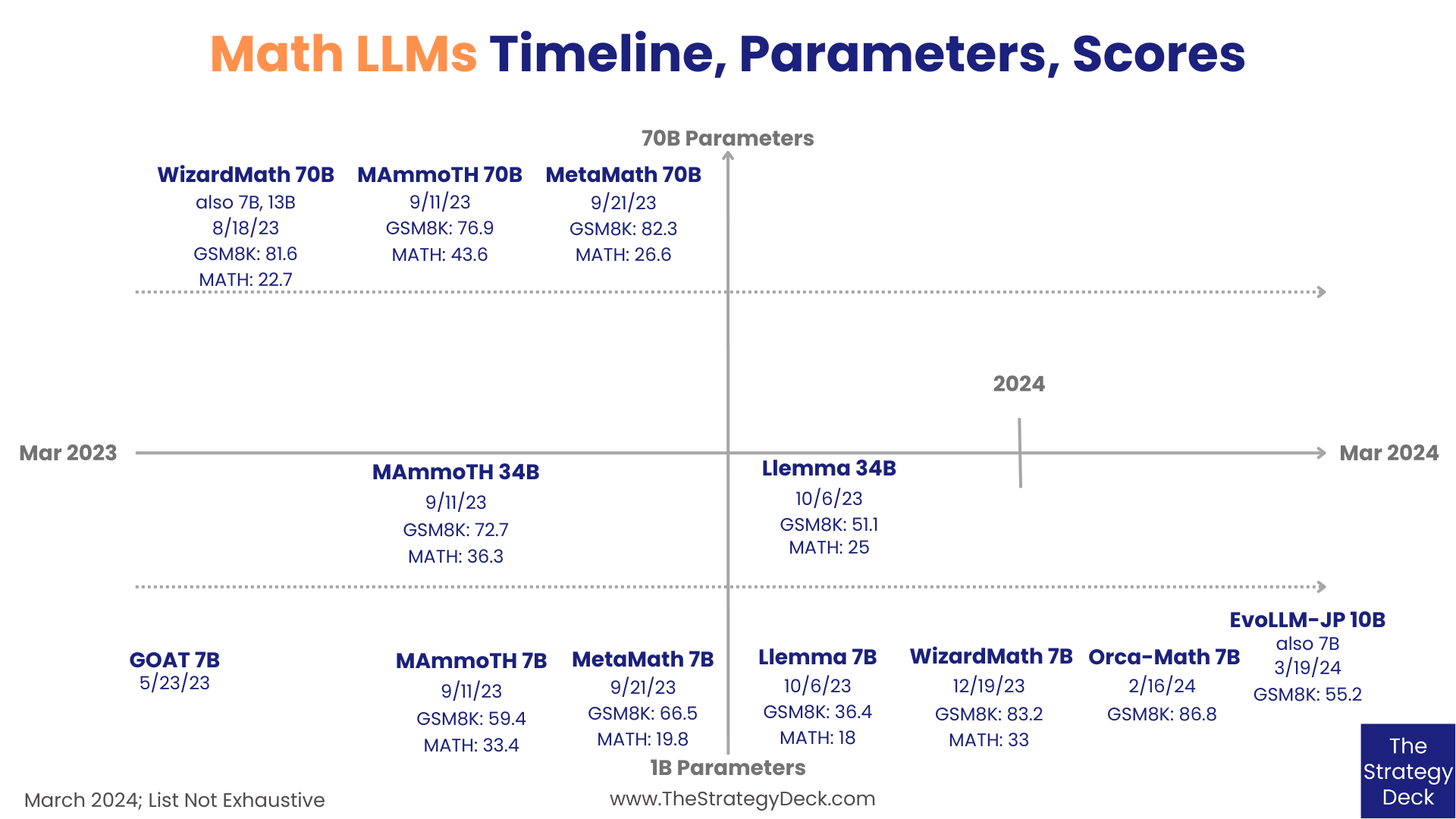
Launched on March 19, 2024, EvoLLM-JP is a Japanese Math Model developed by the Sakana AI research lab in Tokyo, Japan. Available in two versions - 7B and 10B - it was created by merging three open source models, without any additional training. It combines Shisa-Gamma-7B-V1, a General Purpose model in Japanese, WizardMath-7B-V1.1, and Abel-7B-002, both English Math LLMs. All of the three are fine-tuned versions of Mistral 7B.
The model merging method relies on a programmatic, evolutionary algorithm to discover which combinations of base models will be most effective depending on the user’s preferences. It operates in both parameter and data flow spaces and works for cross-domain merging.
EvoLLM-JP 7B scores 52 on MGMS-JP and the 10B achieves 55.2. The model is available on Hugging Face and GitHub and is described in its technical report, titled Evolutionary Optimization of Model Merging Recipes.
Orca-Math - Trained on Synthetic Math Problems Through Iteration
Released on February 16, 2024 by Microsoft Research, Orca-Math is a fine-tuned version of Mistral 7B using 200,000 synthetic math problems and an iterative process, where the model is allowed to practice solving problems and continues to improve based on feeedback.
Orca-Math scores 86.8 on GSM8K. Its training dataset is available on Hugging Face and its technical report is titled Orca-Math: Unlocking the Potential of SLMs in Grade School Math.
Llemma - Continued Pretraining on Math Datasets
Llemma was released on October 16 2023 by researchers at Princeton University, Eleuther AI, University of Toronto, Vector Institute, University of Cambridge, Carnegie Mellon University and University of Washington.
It is a fine-tuned version of Code Llama on Proof-Pile 2, a 55b token collection of scientific papers, web data containing mathematics and mathematical code. Proof-Pile-2 is made up of:
AlgebraicStack, an 11B token dataset of source code in 17 languages, spanning numerical, symbolic and formal math,
OpenWebMath, a 15B token dataset of web pages filtered for mathematical content
28B tokens of the ArXiv subset of RedPajama, which is an open-access reproduction of the Llama training dataset
The 7B version scores 36.4 on GSM8k and 18 on MATH, and the 34B version achieves 51.1 on GSM8K and 25 on MATH.
The model, dataset and code are available on GitHub and the technical report is titled Llemma - An Open Language Model for Mathematics
MetaMath - Fine-Tuned for Mathematical Reasoning
Released on September 21, 2023 by researchers from the University of Cambridge, Southern University of Science and Technology, Hong Kong University of Science and Technology, Huawei, The Alan Turing Institute and the Max Planck Institute for Intelligent Systems, MetaMath is a fine-tuned version of Llama 2.
The model was trained to specialize in mathematical reasoning with the MetaMathQA dataset, which rewrites problems from multiple perspectives and provides both forward and backward reasoning paths. It comes in three versions: 7B, 13B and 70B.
MetaMath 7B scores 66.5 on GSM8K and 19.8 on MATH, the 13B model achieves 72.3 on GSM8K and 22.4 on MATH, and the 70B version gets 82.3 on GSM8K and 26.6 on MATH.
The model, dataset and code are available on GitHub and Hugging Face and the technical report is titled: MetaMath: Bootstrap Your Own Mathematical Questions for Large Language Models.
MAmmoTH - CoT and PoT Fine-Tuning for General Math Problem-Solving
Launched on September 11 2023, MAmmoTH was developed by researchers at the University of Waterloo, The Ohio State University, Hong Kong University of Science and Technology, University of Edinburgh and 01.ai.
Optimized for general math problem-solving, it was trained on MathInstruct, a dataset compiled from 13 sources with intermediate steps in a combination of chain-of-thought (CoT) and program-of-thought (PoT) rationales. CoT contributes its ability to cover most math subjects and handle complex reasoning, and PoT is used to offload the computational process to external tools, such as Python interpreters, in order to deal with advanced procedures. CoT prompting allows LLMs to solve problems incrementally, enhancing accuracy and explainability, while PoT formulates the intermediate reasoning process as a program and exports it to be processed with programming tools.
The base model is fine-tuned from Llama 2 and the Coder version from Code Llama. MAmoTH comes in 7B, 13B, 34B and 70B sizes.
On GSM8k, MAmmoTH-Coder 7B scores 59.4, the 13B version achieves 64.7, the 34B 72.7 and the 70B 76.9. On MATH, the 7B size scores 33.4, the 13B gets 36.3, the 34B 43.6 and the 70B achieves 41.8.
The code, data and models are available on GitHub and Hugging Face and the technical report is titled MAmmoTH - Building math generalist models through hybrid instruction tuning.

WizardMath - Fine-Tuning with Reinforced Evol-Instruct
WizardMath was launched on August 18 2023 by researchers at Microsoft and the Shenzhen Institute of Advanced Technology at the Chinese Academy of Sciences as a fine-tuned version of Llama 2. An additional model, based on Mistral 7B, was released on December 19 2024.
The models are fine-tuned through Reinforcement Learning from Evol-Instruct Feedback adapted for math.
The method has three components:
an Instruction Reward Model that judges the quality of the instructions on definition, precision and integrity
a Process-supervised Reward Model that assesses the correctness of each step in the solutions generated by the model
reinforcement learning via Proximal Policy Optimization
The 70B, Llama 2, version of WizardMath scores 81.6 on the GSM8K benchmark and 22.7 on the MATH benchmark, the 13B achieves 63.9 on GSM8K and 14 on MATH, and the 7B model gets 54.9 on GSM8K and 10.7 on MATH.
The version fine-tuned from Mistral 7B achieves 83.2 on GSM8k and 33.0 on MATH.
The models are available on GitHub and Hugging Face and the techical report is titled WizardMath: Empowering Mathematical Reasoning for Large Language Models via Reinforced Evol-Instruct.
GOAT - Good at Arithmetic Tasks
Launched on May 23 2023, by researchers at the National University of Singapore, GOAT is a 7B model fine-tuned from Llama on synthetic data of 1 million question-answer pairs for arithmetic tasks, including addition, subtraction, multiplication, and division of integers.
The model outperforms GPT-4 on the BIG-bench arithmetic sub-task and it is available on GitHub and Hugging Face. Its technical report is Goat: Fine-tuned LLaMA Outperforms GPT-4 on Arithmetic Tasks.
Comparison with General Purpose LLMs
The open source models in this collection are getting very close to parity with the largest closed source models from OpenAI, Google and Anthropic on popular benchmarks such as GSM8K and MATH.
Specifically, WizardMath 7B scores 83.2 on GSM8k and 33 on MATH, while Orca-Math 7B achieves 86.8 on GSM8K. The closed source large models all score at or above 90 on GSM8K, with GPT-4 at 90, Gemini Ultra at 94.4 and Claude 3 Opus at 95, according to the results reported in their technical papers.
Related Papers
For an even deeper dive into the domain of math-focused AI models, check out:
Large Language Models for Mathematical Reasoning: Progresses and Challenges published January 2024 by researchers from Pennsylvania State University and Temple University
Mathematical Language Models: A Survey released December 2023 by researchers at the East China National University
Do you think math is a domain where LLMs are going to be great in? In it's vanilla form they only predict the most likely next token and with that are quite badly suited for the task. Do you think using something like the code interpreter from OpenAI is the way to go to iteratevly solve problems?